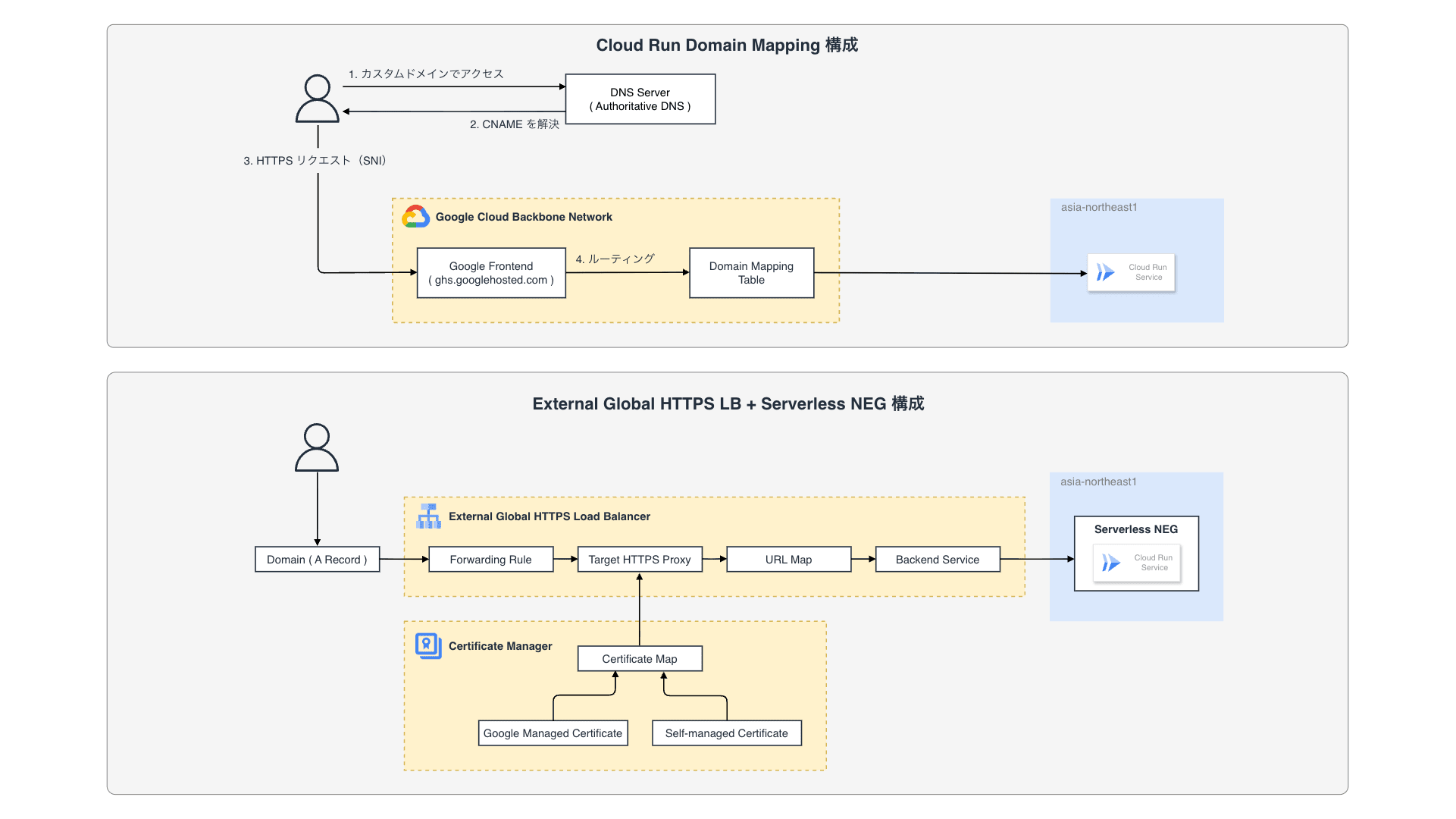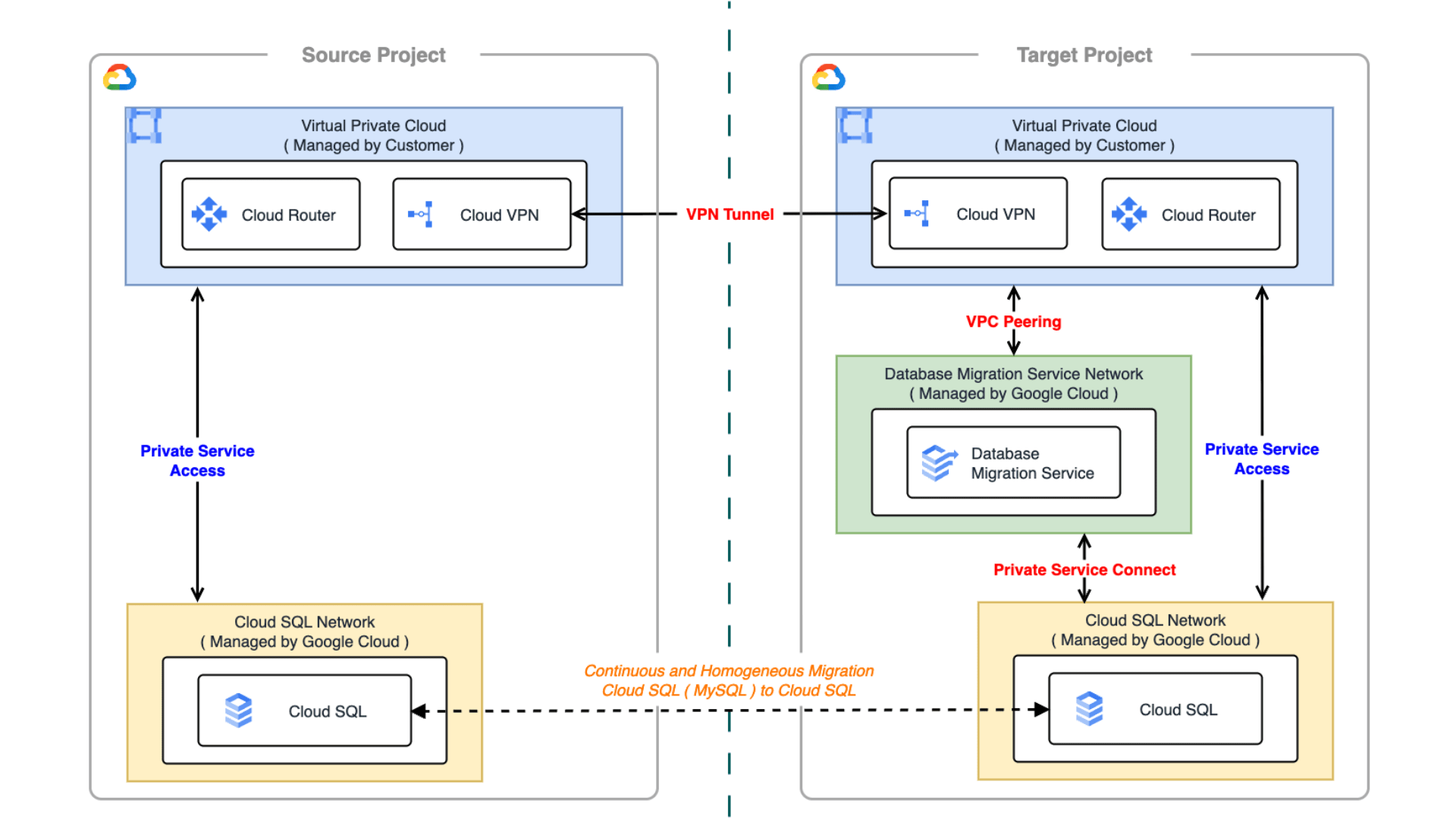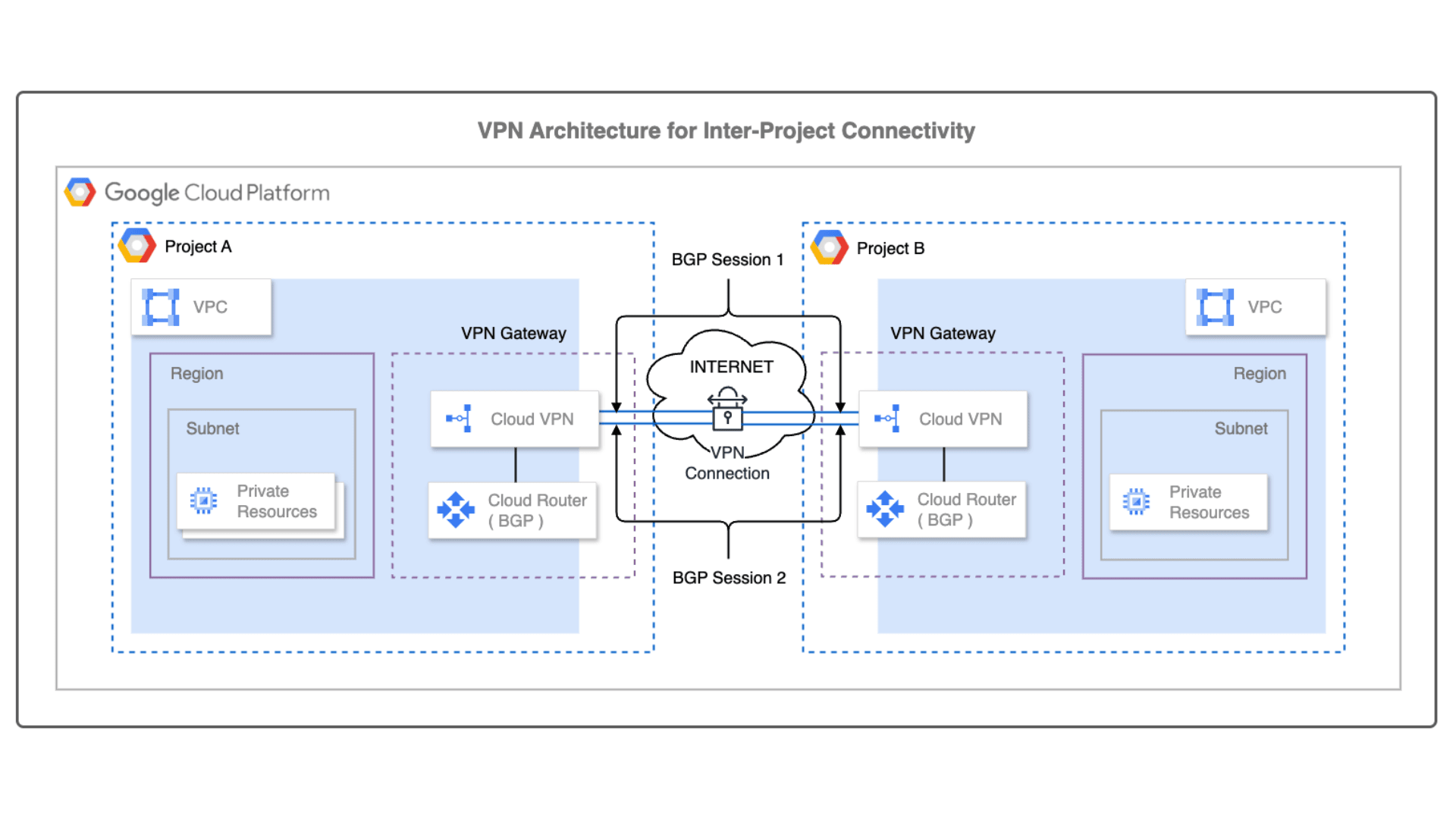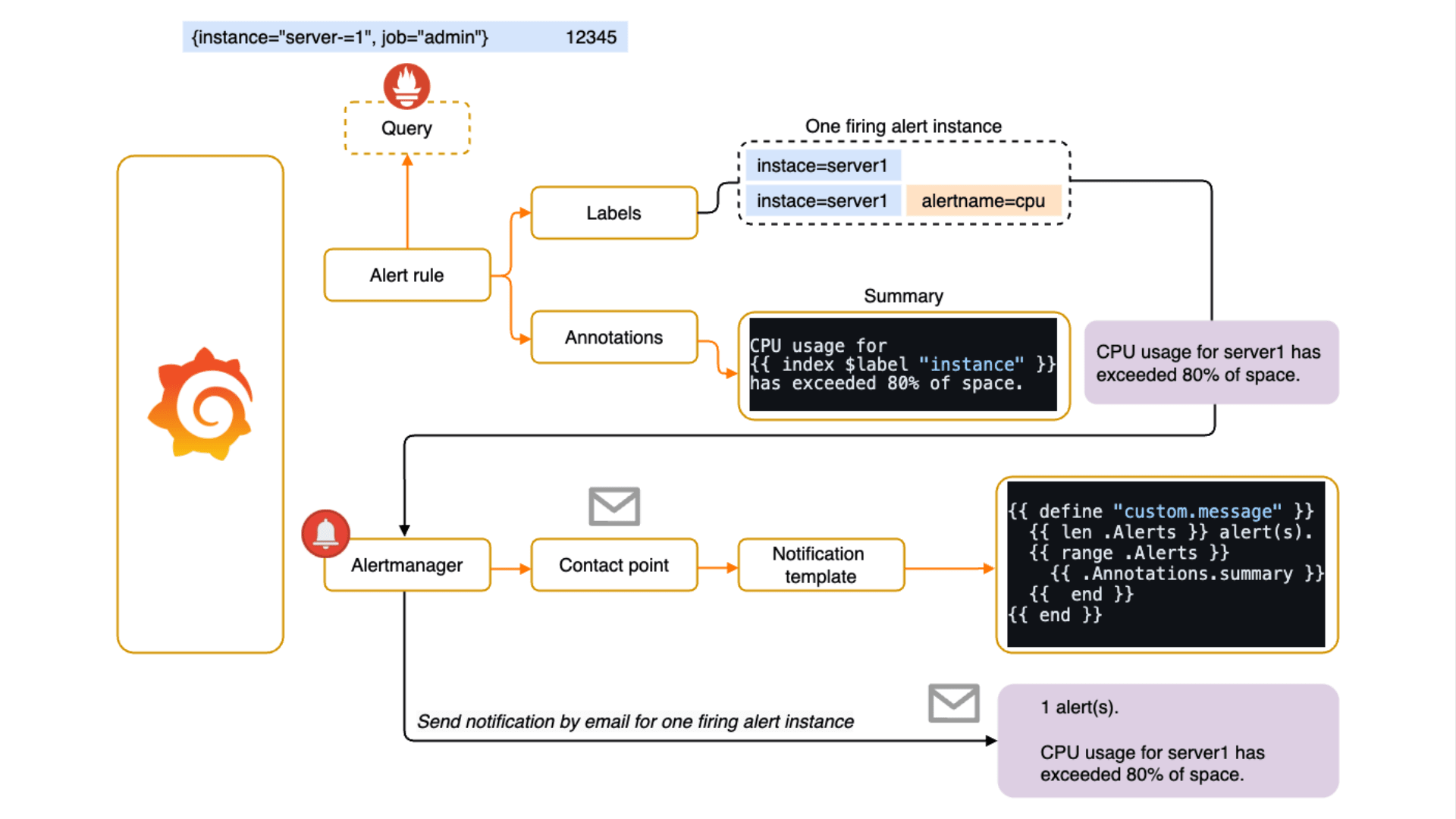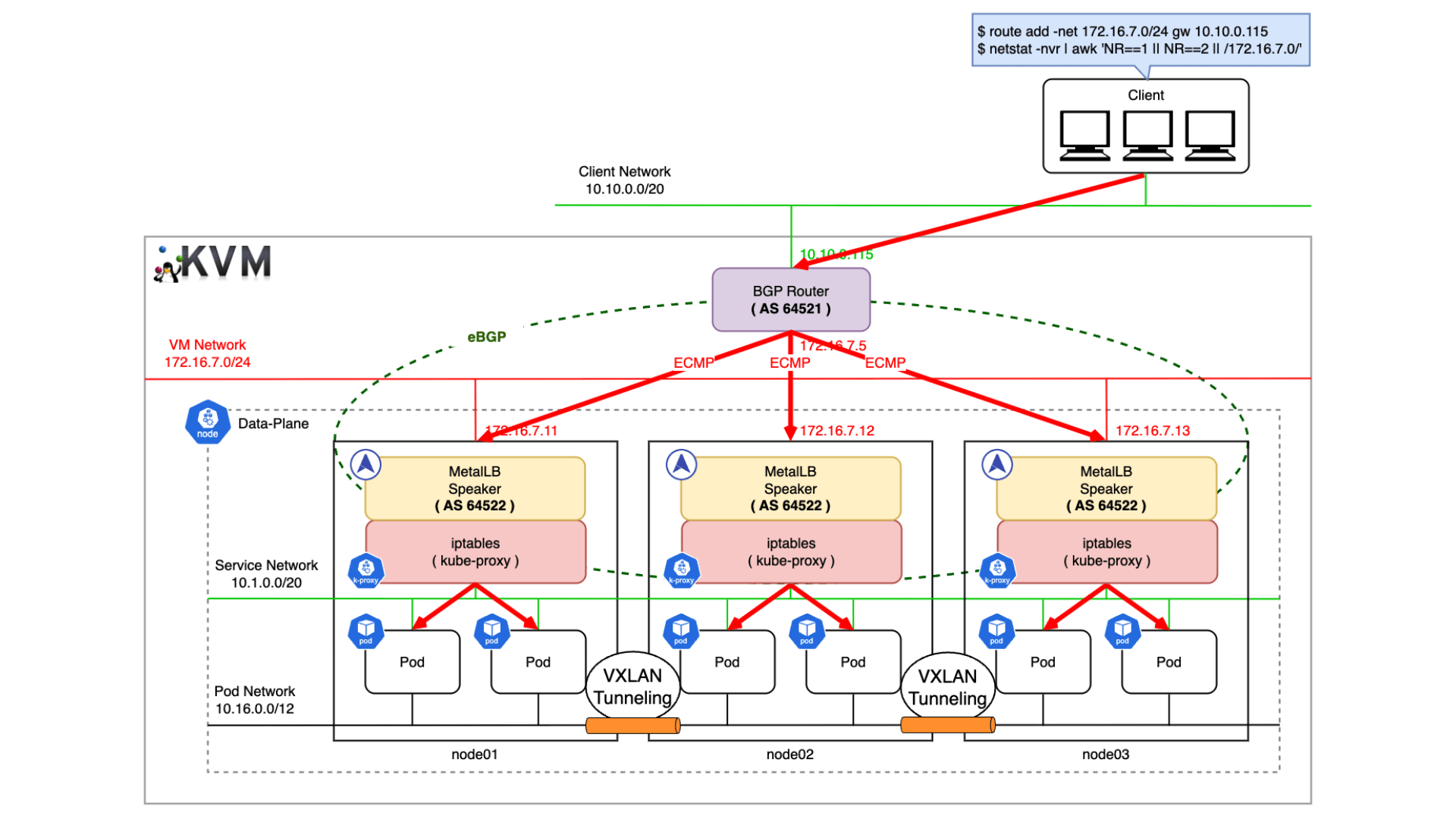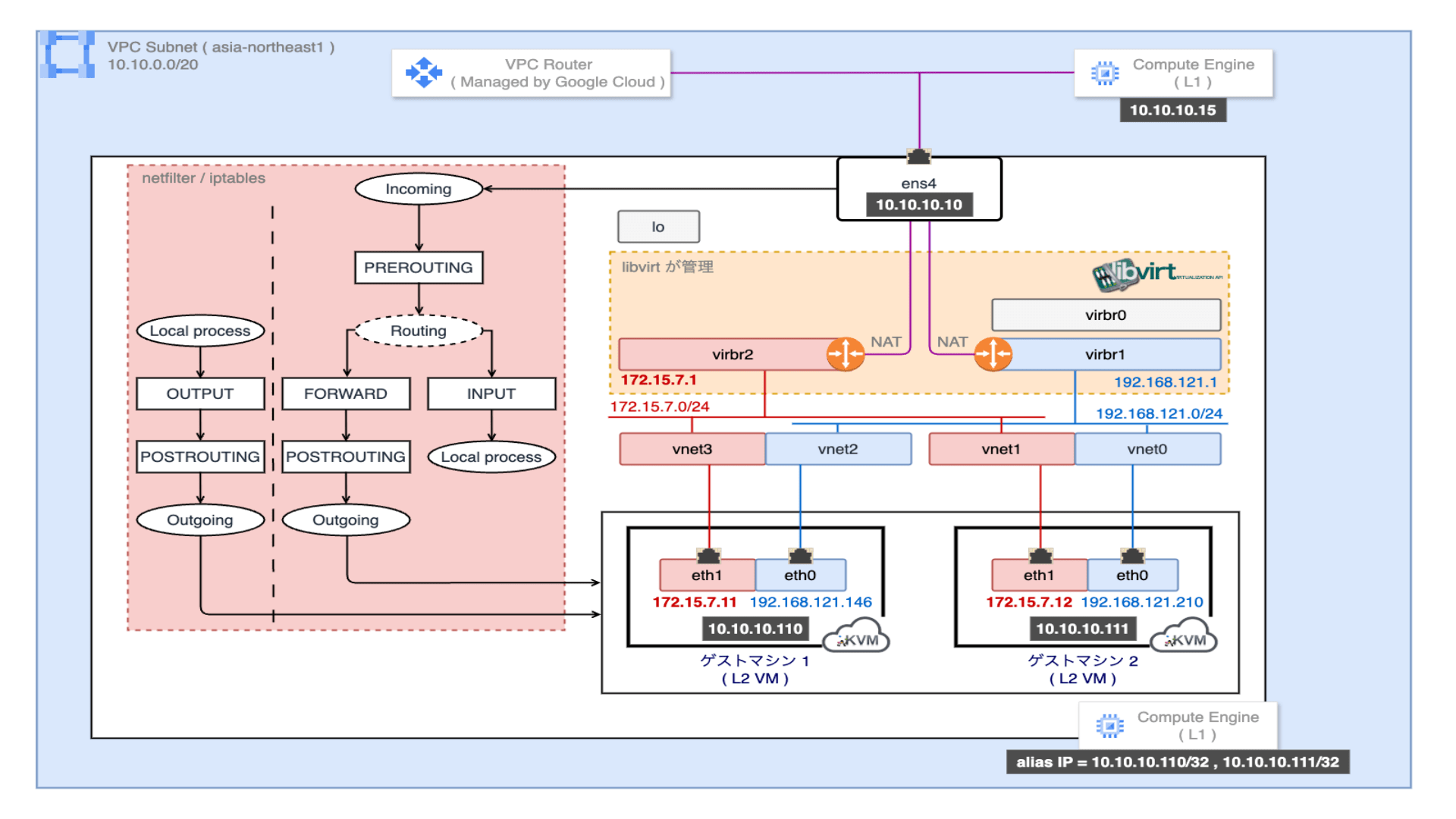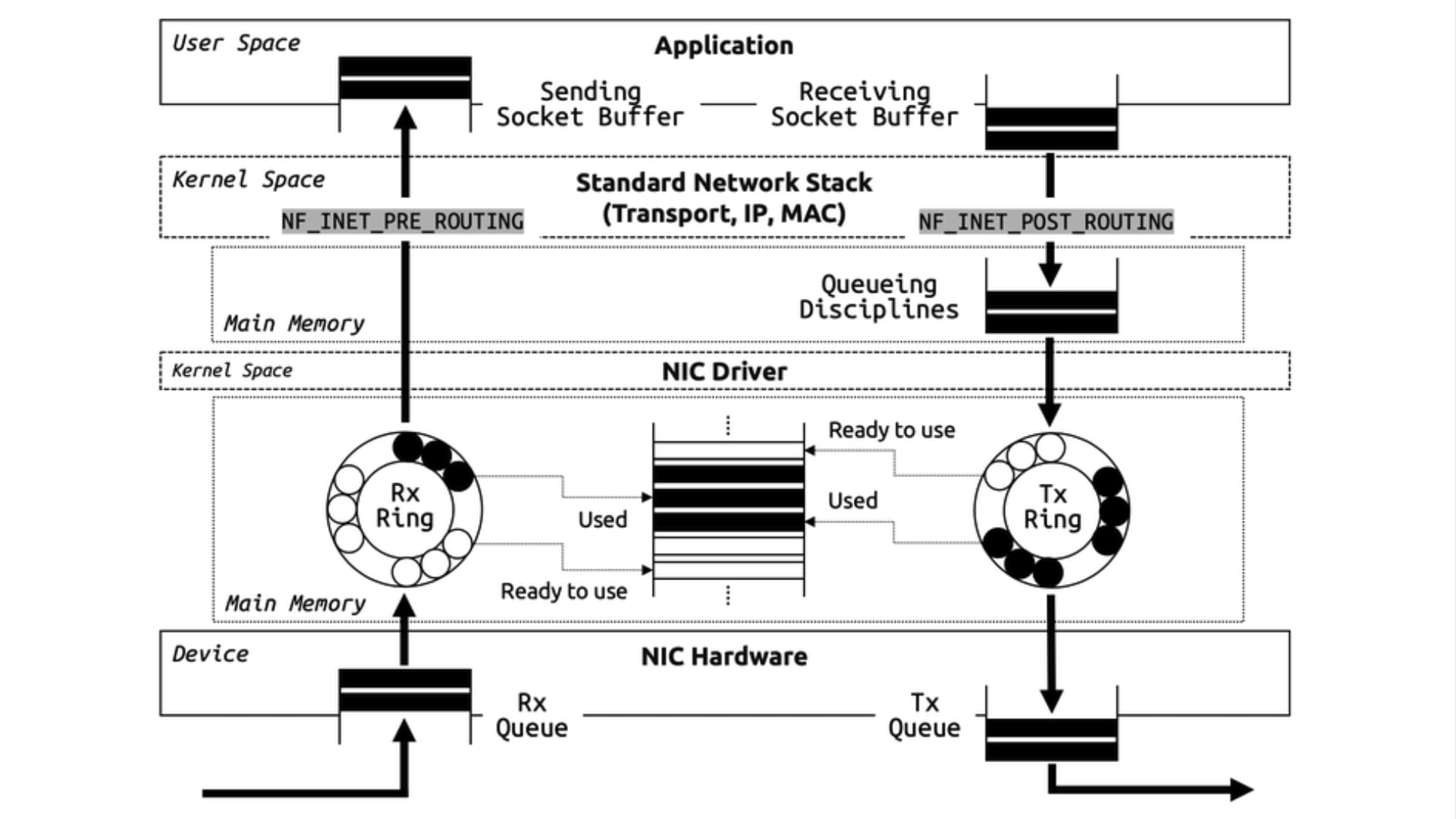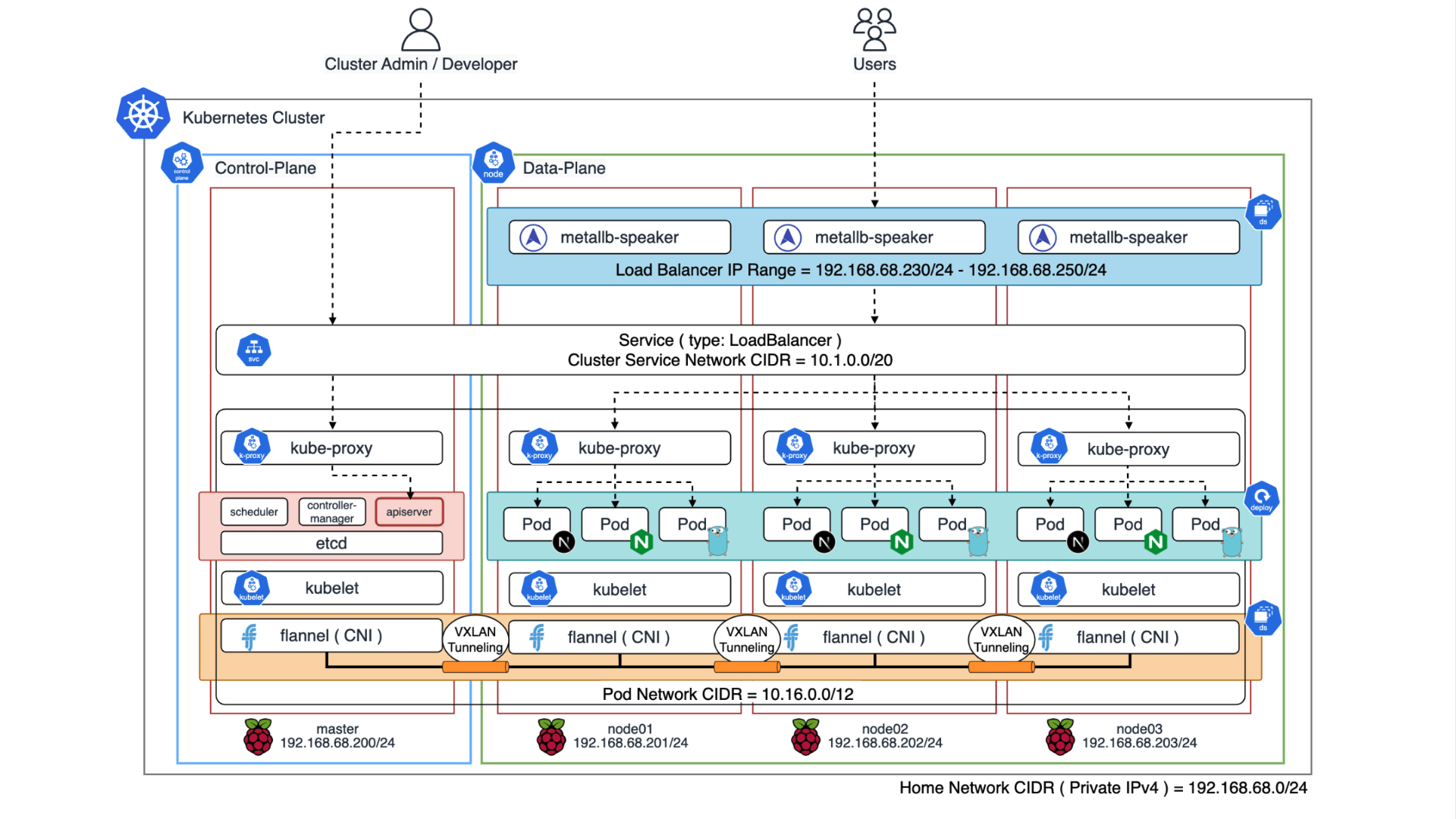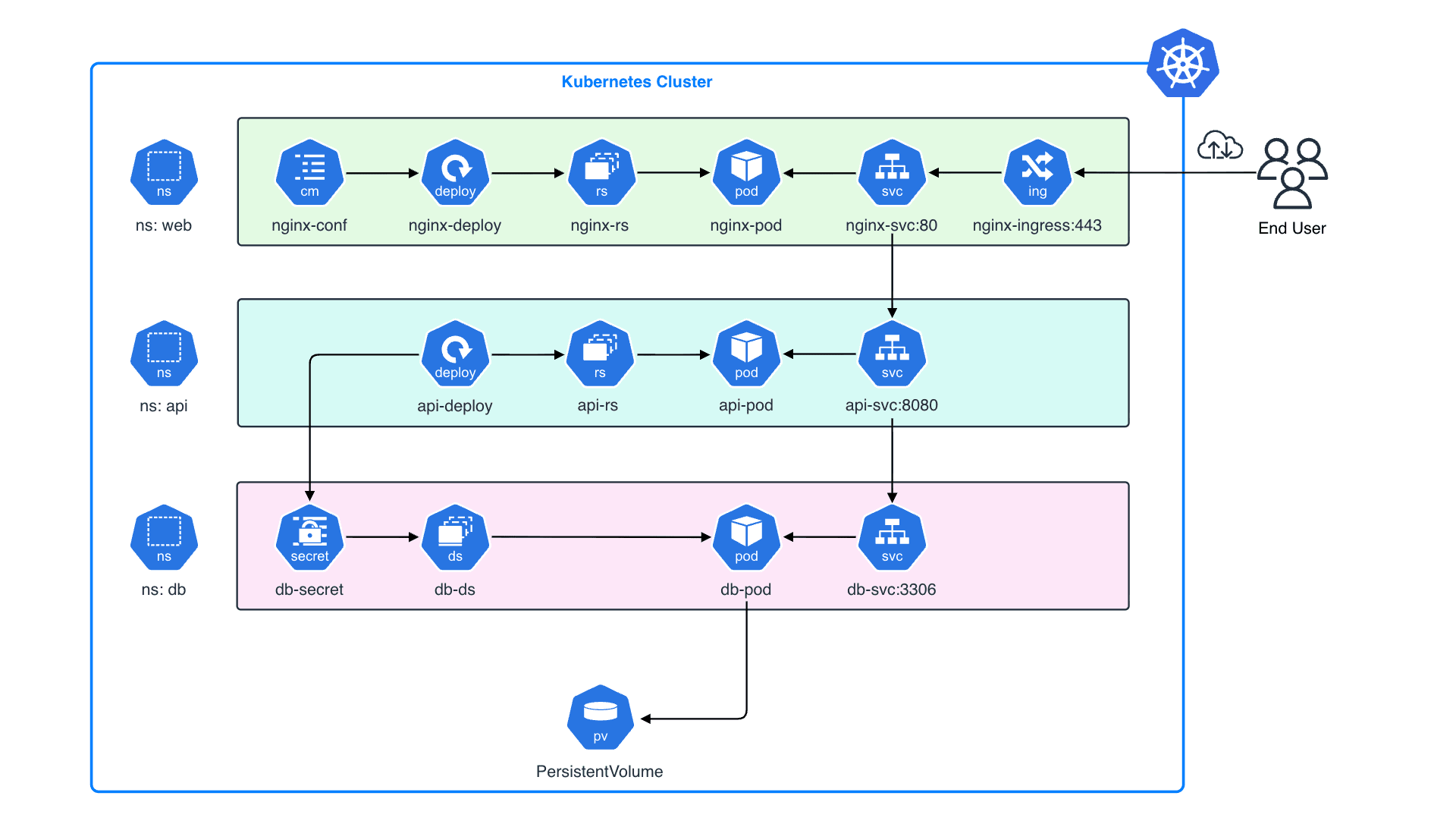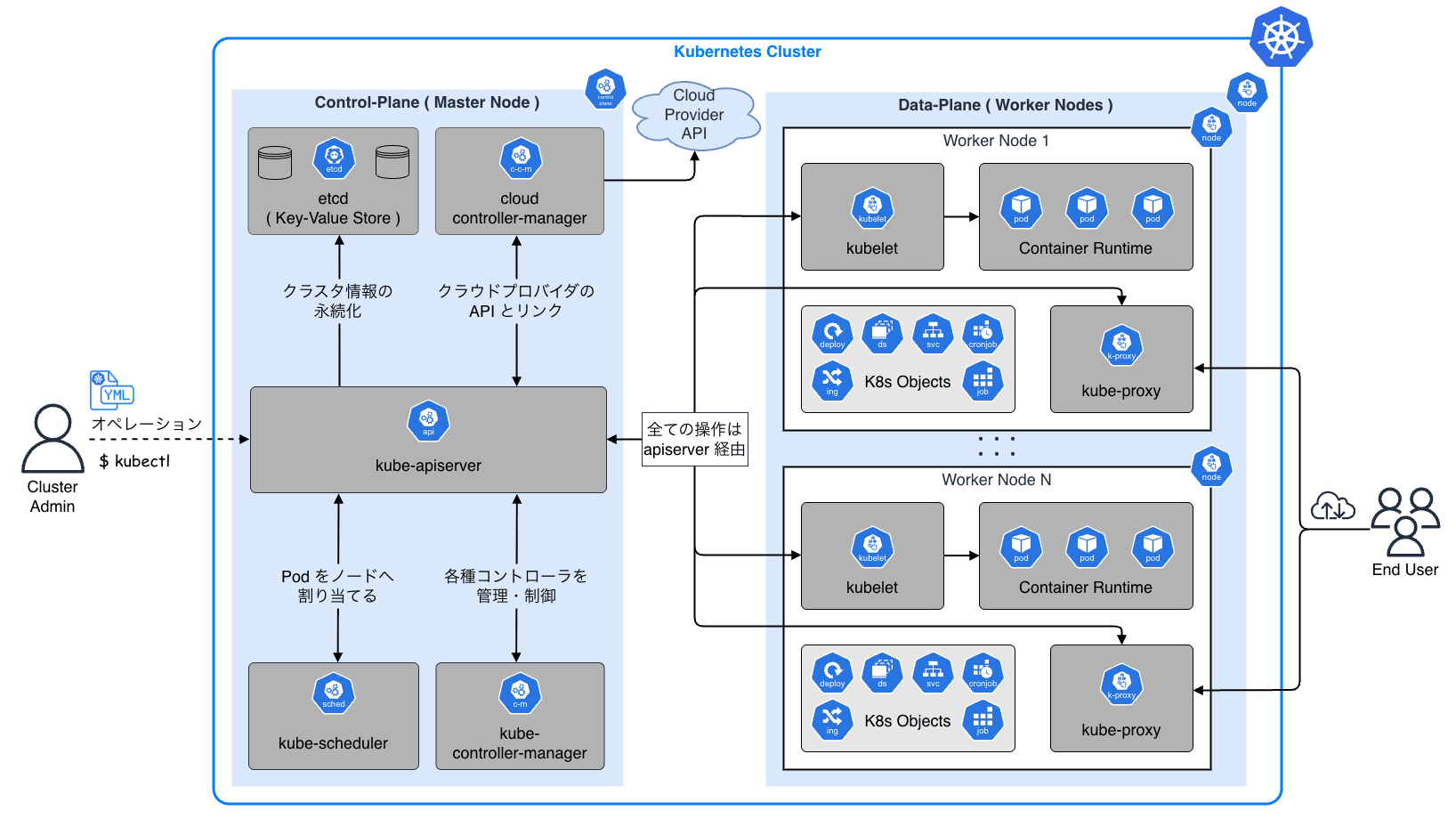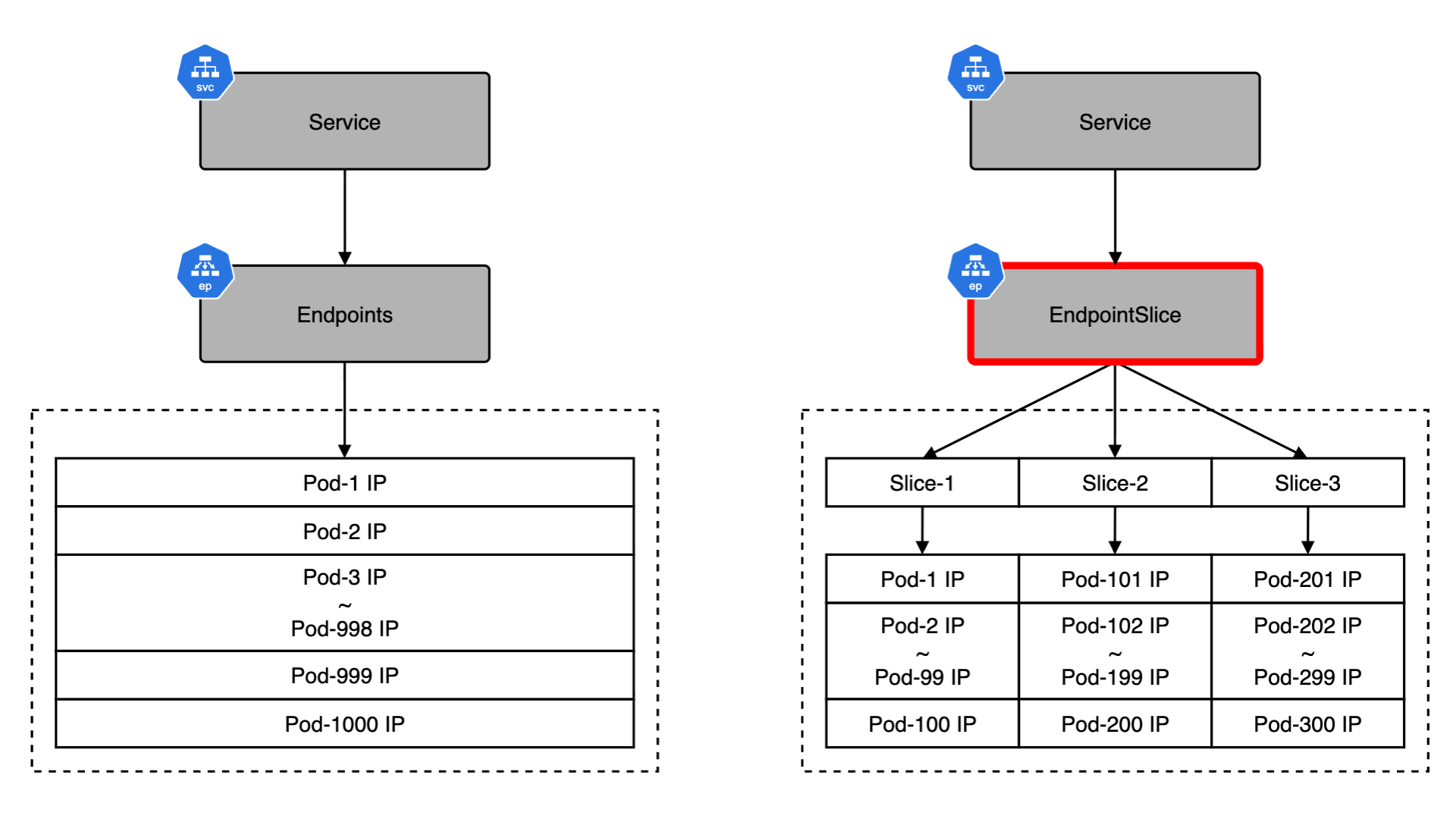
Kubernetes v1.33 では長らく利用されてきた Endpoints API が正式に Deprecated となり、EndpointSlice API が標準化されます。Endpoints / EndpointSlice はどちらも Pod のネットワークエンドポイントを管理するための API です。Endpoints を参照するコンポーネントが存在する場合、どのような影響があるのかについて理解しておく必要があります。例えば、Endpoints から EndpointSlice に移行すると、API グループが core から discovery.k8s.io に変わるため、カスタムコントローラはじめ client-go を利用している場合は、実装そのものを修正する必要があります。また、v1/Endpoints を直接 get / watch / list するコンポーネントの場合、必要に応じて RBAC を修正する必要があります。今回のブログでは、Endpoints と EndpointSlice の違いや、移行することにどのようなメリットがあるのかについて紹介したいと思います。
- Published on